Unlocking KQL: The Language Behind Azure Logs and Monitoring
Unlocking KQL: The Language Behind Azure Logs and Monitoring

In the rapidly moving world of cloud engineering, DevOps, and security operations, chances are you’ve heard someone utter, “Just run a KQL query.” Whether you’re debugging an issue in Azure Monitor or trying to figure out a security incident in Microsoft Sentinel, KQL is becoming a part of your daily toolkit.
But what is KQL, and how does it differ from the standard SQL language that many engineers already know? Let’s take a closer look at what makes KQL so strong—and why it’s becoming a skill everyone wants to have in the cloud-native era.
What is KQL?
KQL is short for Kusto Query Language. It’s a read-only, declarative language created by Microsoft specifically for querying and analyzing lots of data. KQL powers mainstream Azure services such as Log Analytics, Application Insights, and Microsoft Sentinel.
The language is optimized for use cases with structured, semi-structured, and even unstructured data. Whether you’re examining telemetry, troubleshooting performance issues, or tracking security logs, KQL makes it easy to pull useful insights—quickly.
How KQL Is Different From SQL
Whereas SQL is tuned for transactional databases, KQL is optimized for analytics at scale. It’s optimized for speed and scale—perfect for time-series data and logs.
One of the best things about it is its pipe-based syntax. Rather than having to write nested queries, you can divide queries into logical steps and feed the result of one operation as input into the next using a pipe (|). This simplifies the query to read and debug.
Another significant distinction is schema-on-read, where you don’t have to declare a data structure prior to executing your query. This is particularly useful where data formats change quickly—such as log data.
Why KQL is Incredibly Fast
KQL’s speed boils down to how it’s constructed. It uses parallel query execution, spreading the work across many compute nodes to get results more quickly. It also employs columnar storage, reading only what you need—no more fetching whole rows just to get to one field.
Frequently accessed data is cached to reduce load times, and in the background, the query engine does intelligent query optimization, rewriting your query for improved efficiency before it’s even executed. This combination results in blazing-fast analytics at scale.
KQL Architecture: A Look Under the Hood
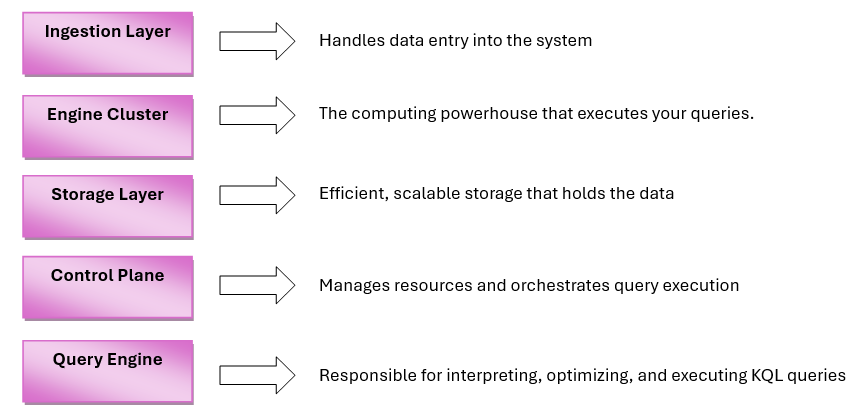
At its base, KQL is driven by Azure Data Explorer (ADX), a cloud-built analytics service designed to support gargantuan volumes of data in real-time. Its design is composed of some key components that each have an important function when it comes to performance and versatility.
The Ingestion Layer enables you to ingest data from multiple sources, ranging from Azure Monitor and Event Hubs to IoT devices and REST APIs. You can ingest data in bulk (batch ingestion) or stream it in real-time (stream ingestion), depending on your scenario.
Engine Cluster is where the magic takes place. This is a group of compute nodes that execute your queries in parallel, providing high performance with enormous datasets.
KQL employs a column-store storage layer, which is optimized for analytics workloads. It is amenable to high compression and rapid data access, particularly with time-series data prevalent in telemetry and monitoring applications.
The Control Plane is responsible for anything from authentication (through Azure Active Directory) to resource assignment and query load balancing. It is also responsible for tasks such as data sharding and partitioning, ensuring data is properly arranged and queries are run efficiently.
Lastly, the Query Engine parses, optimizes, and runs your queries. It reads your query, constructs a logical plan, rewrites it for performance, and then runs it across the engine cluster. It’s an optimized process for speed and scalability.
Writing Your First KQL Query
KQL is read-only, and the syntax is made to be logical and intuitive. Each step of the query is isolated by a pipe (|), so data can flow smoothly through operations.
If you’re just starting out with KQL, there are following few key commands that will form the backbone of most queries. With these limited commands, you are already able to create complex queries in minutes.
- project – Select specific columns
- summarize – Aggregate data (like GROUP BY in SQL)
- extend – Create calculated fields
- where –Filtering
- Sort – Sorting and take – Limiting
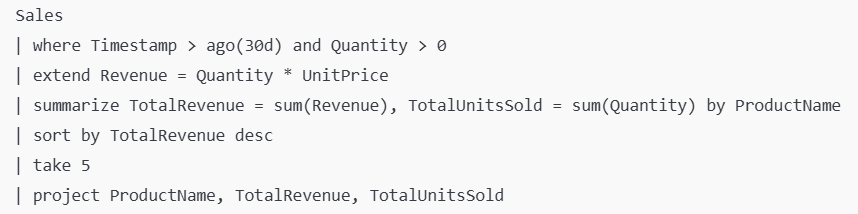
Following example showing how we can build a Powerful KQL Query with Multiple Operators referring “Sales” table.
Why KQL is a Must-Have Skill for Cloud Engineers
In a cloud-native world, speed and simplicity are paramount. KQL puts power in the hands of engineers to rapidly query, visualize, and take action on data—whether you’re keeping an eye on infrastructure, troubleshooting application problems, or drilling into a security incident.
KQL isn’t a nicety for DevOps engineers, SREs, and cloud architects. It’s a must-have. Dominating it means fewer educated guesses and more actionable information, quicker decision-making, and a stronger grip on your cloud environment.
Final Thoughts
KQL is more than a query language—it’s a smarter way to work in the cloud. With its simple syntax, high-performance design, and deep integration with Azure, it’s no wonder that it’s gaining traction as an industry standard for log and telemetry analysis.
So if you’re working in the Microsoft cloud ecosystem and haven’t started learning KQL yet, now is the perfect time. Your future self—and your team—will thank you.