Revealing Apache Iceberg: The Future of Big Data Management and Data Lakes
Revealing Apache Iceberg: The Future of Big Data Management and Data Lakes

In today’s digital economy, data is the most valuable asset for businesses—especially in industries like e-commerce, where real-time customer behavior, transactions, inventory, and marketing data drive decision-making. Yet, managing such vast, dynamic datasets efficiently and reliably is one of the biggest technical challenges.
This is where Apache Iceberg comes in—a modern, high-performance table format that has redefined the way big data systems are built. The Apache Iceberg brings data warehouse-like reliability to cloud-native data lakes, enabling modern analytics at scale. Let’s take a look at why it’s becoming a must-have tool in data analytics.
What is Apache Iceberg?
Apache Iceberg is an open-source table format, OTF (Open Table Format), created in 2017 at Netflix by Ryan Blue and Daniel Weeks. This project was open-sourced and donated to Apache Software Foundation in 2018.
Apache Iceberg is not just an open-source table format but it is a transformative tool which addresses many of the limitations of traditional table formats like Apache Parquet and Apache ORC, related to scalability, schema adaptability, and reliability in distributed systems. Iceberg bridges the gap between cloud-native data lakes and traditional data warehouses. It enables organizations to store data with the flexibility of a lake and the organization of a warehouse—without compromising performance or governance. With SQL compatibility and support for leading engines such as Spark, Trino, Flink, and Dremio, Iceberg provides effortless access to huge datasets without the overhead of legacy table formats.
How Apache Iceberg Works
Apache Iceberg presents a clean, modular design that splits table metadata management from physical storage of data. This separation is very efficient and scalable.
There are 3 layers in the architecture of an Iceberg table:
- The Catalog Layer
- The Metadata Layer
- The Data Layer
Here’s an architectural diagram of the structure of an Iceberg table:
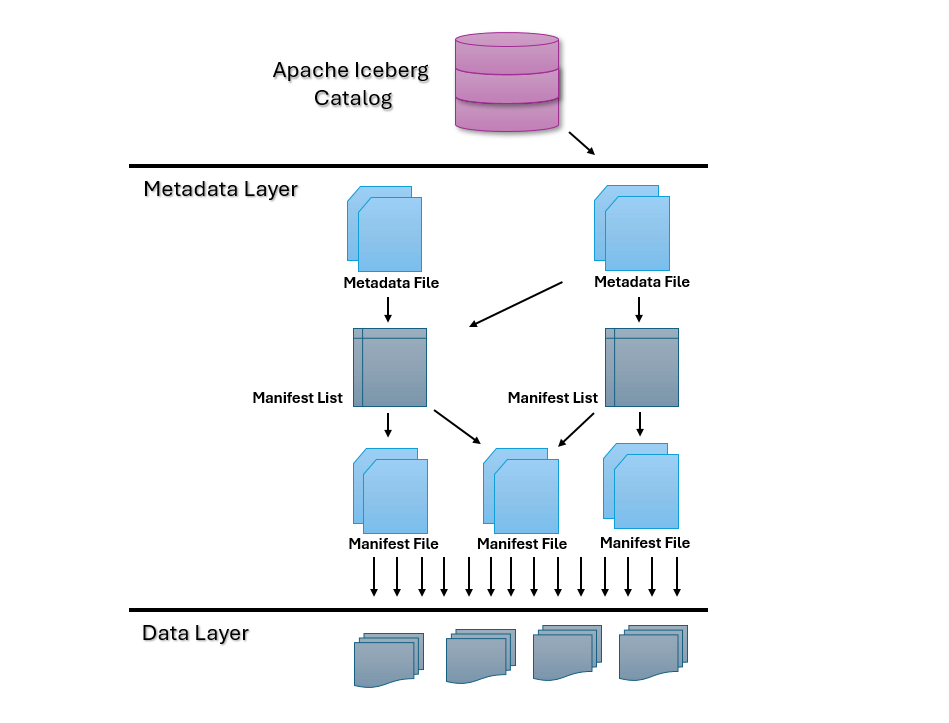
1. Catalog Layer
The catalog handles table discovery and management. It acts as a bridge between query engines and Iceberg tables. Iceberg supports various catalog implementations like Hive Metastore, AWS Glue, and REST-based catalogs, making it highly adaptable to existing infrastructure.
2. Metadata Layer
This is where Iceberg truly shines. Metadata is broken into:
- Metadata Files: Hold schema details, partitioning info, and snapshot history.
- Manifest Files: Follow data files and their metrics—such as path, record count, and partition values.
- Manifest Lists: Act as manifests’ directories, assisting Iceberg in finding and processing pertinent data for every query efficiently.
3.0Data Layer
The underlying data is held in immutable file formats like Parquet, Avro, or ORC. Iceberg doesn’t write to these files directly—instead, it creates new files on each update, maintaining data integrity and supporting features such as rollback and time travel.
Key Features That Set Apache Iceberg Apart
Apache Iceberg brings a set of innovations that make it well-suited for today’s data engineering:
Key Features |
|
| ACID Transactions | Ensures consistent reads and writes, snapshot isolation, and concurrent user operations—vital for multi-tenant analytics environments. |
| Schema Evolution | Quickly change schemas (add, remove, or rename columns) without breaking downstream queries or rewriting history data. |
| Partition Evolution | Modify partitioning schemes over time without reprocessing full datasets. |
| Time Travel | Query historical versions of a table by accessing prior snapshots—a valuable feature for debugging or auditing. |
| Hidden Partitioning | Automates partition logic, eliminating the need to include partition columns in every query manually. |
| Cloud-Native Design
|
Optimized for object stores like Amazon S3, handling eventual consistency and other cloud-specific behaviors more gracefully than legacy formats. |
Top Use Cases for Apache Iceberg
Apache Iceberg is a versatile tool designed to support a wide range of data-driven applications, from advanced analytics to machine learning.
Data Lakehouse
One of its most powerful applications is in constructing data lakehouses, where it takes raw, unstructured cloud storage and converts it into structured, query-able environments. This enables organizations to execute SQL-based analytics and machine learning workloads natively on their data lakes, obviating the expense and inflexibility normally found in legacy data warehouses.
Big Data Analytics
Iceberg is also very strong on petabyte-scale big data analysis, supporting easy integration with state-of-the-art processing engines such as Apache Spark and Flink to manage large-scale data transformations and intricate queries with excellent performance.
Data Governance
Aside from analytics, Iceberg contributes significantly to data governance and compliance. Its assistance for capabilities such as time travel, schema evolution, and partition pruning automatically optimizes organizations, particularly those with regulated industries, to keep history snapshots of their data, enforce retention policies, and provide traceability of the data for compliance and auditing requirements.
Conclusion: The Future is Iceberg
As data warehouses become increasingly obsolete, and organizations move toward scalable, cloud-native lakehouses, Apache Iceberg is an exemplary technology to build upon. Its data management model based on modern architecture and excellent performance and governance capabilities make it the most sought-after solution for innovative data teams.
Whether you’re executing sophisticated analytics, constructing real-time dashboards, or imposing data governance at scale, Apache Iceberg enables you to get more out of your data—efficiently and reliably.