Customer Segmentation using K-Means Clustering: A Guide to Personalizing Marketing Strategies
Customer Segmentation using K-Means Clustering: A Guide to Personalizing Marketing Strategies

In this highly competitive marketplace, information related to customer behaviour is the backbone of business success. Among all of the methods through which firms gain insight into customers’ preferences and behaviours, the method related to Customer Segmentation can be taken as one of the most effective means of subdividing a broad customer base into distinct segments that share similar characteristics or behaviours. Businesses can use these insights, therefore, to devise more effective marketing strategies and to strengthen their customer retention in order to boost profitability.
Perhaps the most influential tool of Customer Segmentation is K-Means clustering, one of the most popular algorithms in machine learning. In this article, we’ll briefly explain to our readers what K-Means clustering is, how it operates, and how this algorithm can be leveraged by businesses to have an effective view of their customer base.
What is K-Means Clustering?
K-Means is an unsupervised type of machine learning, where data points (customers, in this case) will be clustered into a predefined number of clusters based on similarities. Minimizing the variance within clusters and maximizing the variance among the clusters would form the objective.
The “K” in K-Means stands for the number of clusters you want the algorithm to form, and “Means” refers to the centroid or the centre of a cluster.
How Does K-Means Clustering Work?
Here’s a step-by-step explanation of how K-Means clustering works:
Step-1: Initialisation of Centroids: Choose random points (customers) that are going to be the initial centroids-centres of clusters.
Step-2: Classify Points to Nearest Centroid: Place each data point (customer) to the nearest centroid based on similarity measure generally distance Euclidean.
Step-3: Recompute Centroids: Compute new centroids as the average of all data points assigned to that cluster.
Step-4: Repeat: Repeat steps 2 and 3 until the centroids no longer change or the change is minimal, meaning that the algorithm has converged.
Essential Factors to Keep in Mind When Applying K-Means Clustering
While K-Means clustering is a powerful tool, there are some important considerations to keep in mind:
Choosing the Right Value for K
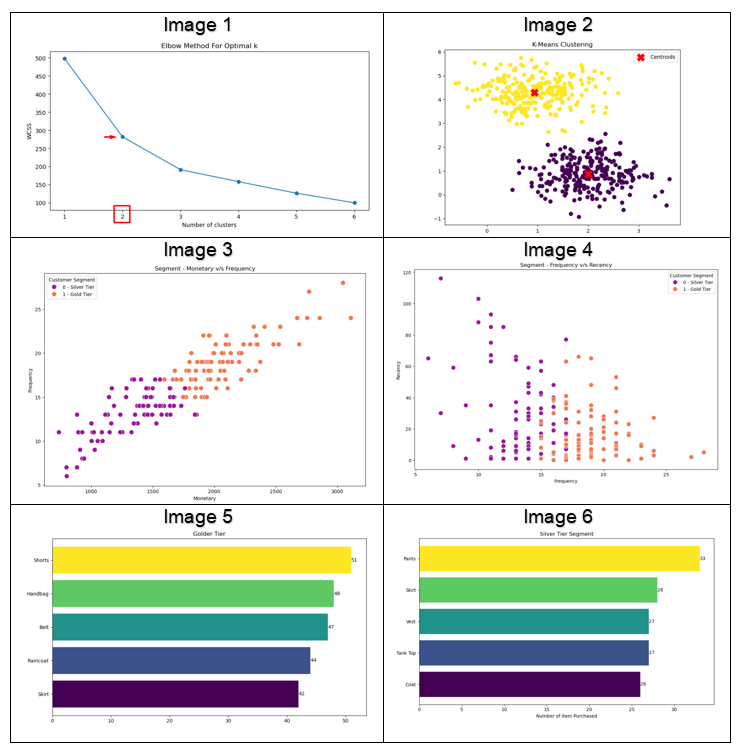
One of the biggest challenges with K-Means clustering is determining the optimal number of clusters (K). If K is too high or too low, the segmentation may be ineffective. Techniques like the Elbow Method or Silhouette Analysis can help you choose the ideal number of clusters by measuring the variance within the clusters.
Data Preprocessing
K-Means requires numerical data and can be sensitive to the scale of the features. Therefore, it’s essential to normalize or standardize the data before running the algorithm to ensure that features with larger values don’t dominate the clustering process.
Outliers
Outliers can skew the results of K-Means clustering, as the algorithm tries to minimize variance within the clusters. Identifying and handling outliers before clustering can improve the accuracy of the segmentation.
Steps to Implement K-Means Clustering for Customer Segmentation
Step 1: Data Collection
Gather customer data or that demographic, purchase history, behavior on your website, or any other relevant metrics you have.
Step 2: Data Preprocessing
Clean the data by removing missing values, normalizing numerical variables, and encoding categorical variables if needed.
Step 3: Choosing K
Determine the ideal number of clusters by using methods such as the Elbow Method or Silhouette Analysis.
Step 4: Apply K-Means Algorithm
Run K-Means algorithm on your customers for segmentation
Step 5: Interpret Results
Interpret segmentation in meaningful labels as per how the customer derives his or her characteristics.
Step 6: Develop Targeted Strategies
Based on the segmentation, formulate targeted marketing campaigns, promotions, or recommendations of products for specific customer groups.
Benefits of K-Means in Customer Segmentation
Informed Decision with Data
The K-Means algorithm does not use any assumption concerning the behavior of customers. Patterns in the customer data that would otherwise not be seen are picked up, and insights can lead to valuable knowledge of how these segments engage with your brand. This happens to be the tool through which a business discovery hidden segments that otherwise would never have been obvious to them.
Targeted Marketing Strategies
Once you have done segmentation of your customers, you can then tailor the marketing campaign to suit each of the segments. Thus, for example, if one segment is highly price sensitive while another is mostly brand loyal, you can craft different messages, offers, and incentives for each of the groups.
Improved Retention of Customers
You can serve unique requirements and preferences of particular customer segments so well. Customers would feel appreciated and responded to appropriately, putting them likely to stick to your brand.
Optimized Resource Allocation
Segmentation allows a company to make adequate resource allocations. The most important resources are marketing budget mostly that can be thrust more on the costly customer segments and smaller cost-intensive strategies applied towards lesser profitable segments.
Real-world Use Case of K-Means Clustering
Let’s take an example from “Fashion Retail Business”.
With the K-Means Clustering technique applied to the dataset, we were able to categorize the customers clearly into the Gold Tier and the Silver Tier customers, with the best clustering being done using the Elbow Method.
We then conducted RFM Analysis (Recency, Frequency, and Monetary) to better understand customer behavior. Insights revealed that Shorts were popular among Gold Tier customers, while Pants were favored by Silver Tier customers.
Interestingly, Skirts were a common favorite across both segments. These insights provide the foundation for targeted marketing strategies, helping brands optimize their campaigns and drive higher conversion rates through personalized approaches.
Conclusion
Customer segmentation using K-Means clustering is an effective way to identify distinct customer groups and personalize your marketing efforts. By applying this powerful algorithm, businesses can uncover insights that drive more effective strategies, improve customer engagement, and increase profitability. Whether you’re in e-commerce, banking, or any other industry, K-Means clustering provides a data-driven approach to understanding your customers and delivering value in a way that resonates with each unique segment.
By following best practices and leveraging K-Means clustering for customer segmentation, you can make more informed decisions, refine your marketing strategies, and foster stronger relationships with your customers. Start using K-Means today to unlock the full potential of your customer data and take your marketing to the next level!